| Citation: | Longqi Li, Yunhuang Yang, Tianzhi Zhou, Mengyun Wang. Data-Driven Combination-Interval Prediction for Landslide Displacement Based on Copula and VMD-WOA-KELM Method. Journal of Earth Science, 2025, 36(1): 291-306. doi: 10.1007/s12583-021-1555-3

|
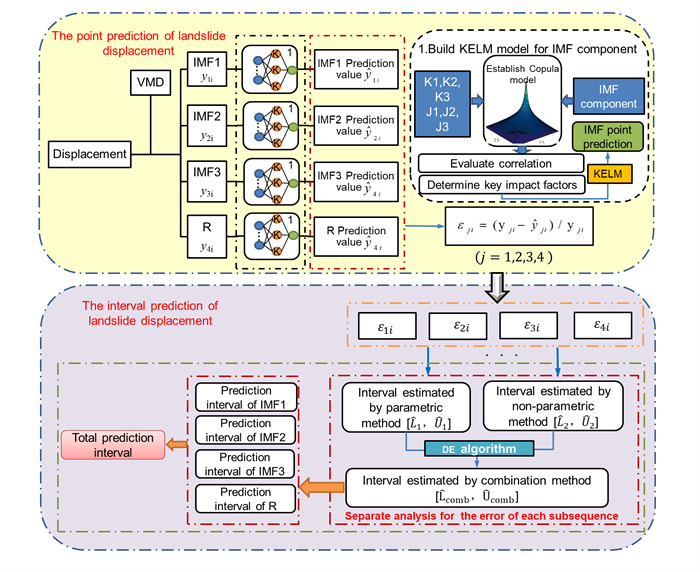
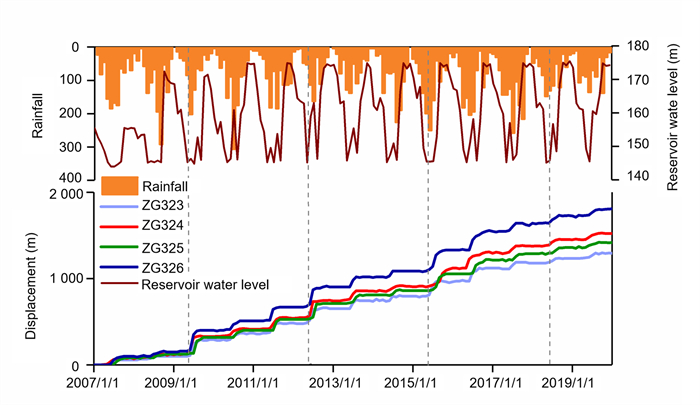
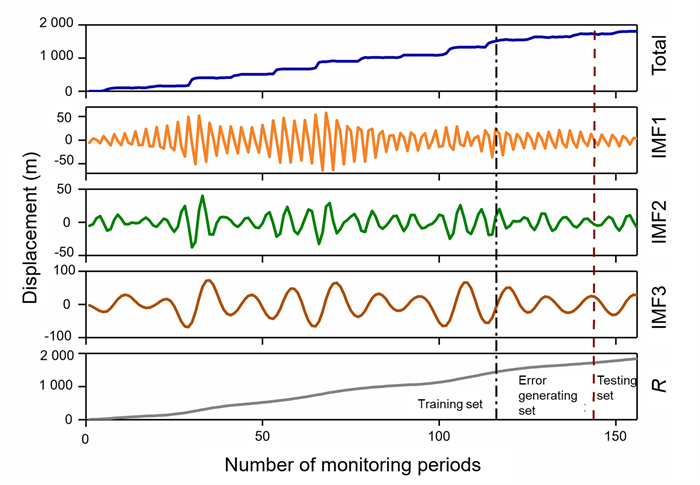
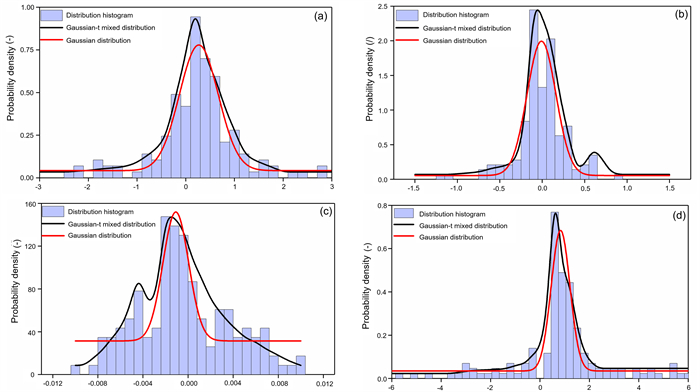
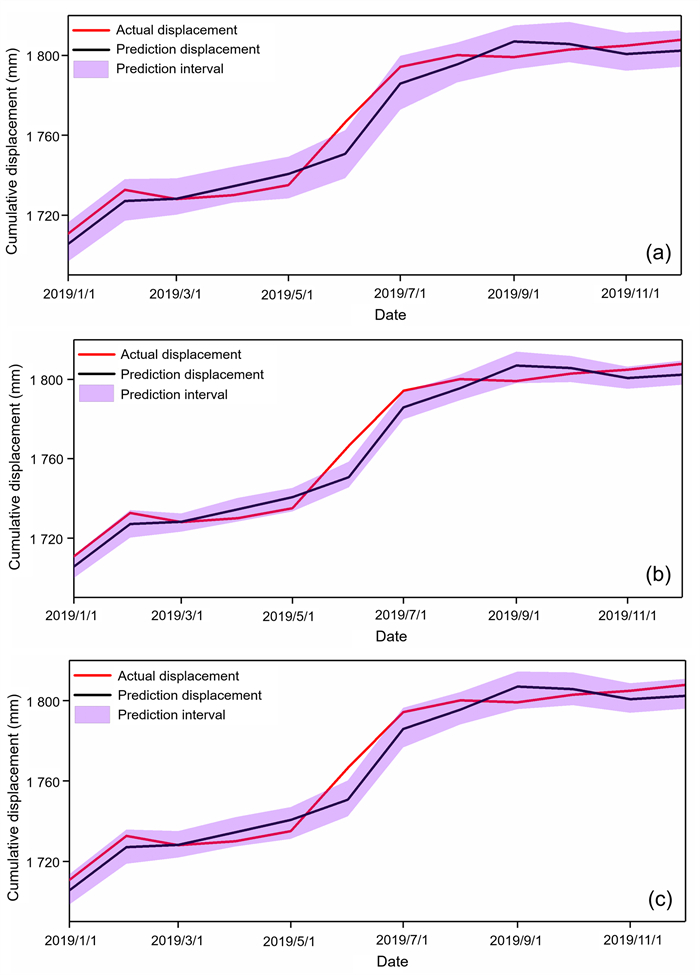
To tackle the difficulties of the point prediction in quantifying the reliability of landslide displacement prediction, a data-driven combination-interval prediction method (CIPM) based on copula and variational-mode-decomposition associated with kernel-based-extreme-learning-machine optimized by the whale optimization algorithm (VMD-WOA-KELM) is proposed in this paper. Firstly, the displacement is decomposed by VMD to three IMF components and a residual component of different fluctuation characteristics. The key impact factors of each IMF component are selected according to Copula model, and the corresponding WOA-KELM is established to conduct point prediction. Subsequently, the parametric method (PM) and non-parametric method (NPM) are used to estimate the prediction error probability density distribution (PDF) of each component, whose prediction interval (PI) under the 95% confidence level is also obtained. By means of the differential evolution algorithm (DE), a weighted combination model based on the PIs is built to construct the combination-interval (CI). Finally, the CIs of each component are added to generate the total PI. A comparative case study shows that the CIPM performs better in constructing landslide displacement PI with high performance.
| Cao, Y., Yin, K. L., Alexander, D. E., et al., 2016. Using an Extreme Learning Machine to Predict the Displacement of Step-Like Landslides in Relation to Controlling Factors. Landslides, 13(4): 725–736. https://doi.org/10.1007/s10346-015-0596-z |
| Corominas, J., Moya, J., Ledesma, A., et al., 2005. Prediction of Ground Displacements and Velocities from Groundwater Level Changes at the Vallcebre Landslide (Eastern Pyrenees, Spain). Landslides, 2(2): 83–96. https://doi.org/10.1007/s10346-005-0049-1 |
| Deng, D. M., Liang, Y., Wang, L. Q., et al., 2017. Displacement Prediction Method Based on Ensemble Empirical Mode Decomposition and Support Vector Machine Regression—A Case of Landslides in Three Gorges Reservoir Area. Rock and Soil Mechanics, 38(12): 3660–3669. https://doi.org/10.16285/j.rsm.2017.12.034 (in Chinese with English Abstract) |
| Dragomiretskiy, K., Zosso, D., 2014. Variational Mode Decomposition. IEEE Transactions on Signal Processing, 62(3): 531–544. https://doi.org/10.1109/TSP.2013.2288675 |
| Du, J., Yin, K. L., Lacasse, S., 2013. Displacement Prediction in Colluvial Landslides, Three Gorges Reservoir, China. Landslides, 10(2): 203–218. https://doi.org/10.1007/s10346-012-0326-8 |
| Gao, Q. Y., 2019. Study on Combination of Risk Probability Rainfall Threshold of Flash Flood in Small Watershed Based on Copula Function: [Dissertation]. Zhengzhou University, Zhengzhou. 54–60 (in Chinese with English Abstract) |
| Herrera, G., Fernández-Merodo, J. A., Mulas, J., et al., 2009. A Landslide Forecasting Model Using Ground Based SAR Data: The Portalet Case Study. Engineering Geology, 105(3/4): 220–230. https://doi.org/10.1016/j.enggeo.2009.02.009 |
| Huang, F. M., Huang, J. S., Jiang, S. H., et al., 2017. Landslide Displacement Prediction Based on Multivariate Chaotic Model and Extreme Learning Machine. Engineering Geology, 218: 173–186. https://doi.org/10.1016/j.enggeo.2017.01.016 |
| Huang, G. B., 2003. Learning Capability and Storage Capacity of Two-Hidden-Layer Feedforward Networks. IEEE Transactions on Neural Networks, 14(2): 274–281. https://doi.org/10.1109/TNN.2003.809401 |
| Huang, G. B., Chen, L., Siew, C. K., 2006a. Universal Approximation Using Incremental Constructive Feedforward Networks with Random Hidden Nodes. IEEE Transactions on Neural Networks, 17(4): 879–892. https://doi.org/10.1109/tnn.2006.875977 |
| Huang, G. B., Zhu, Q. Y., Siew, C. K., 2006b. Extreme Learning Machine: Theory and Applications. Neurocomputing, 70(1/2/3): 489–501. https://doi.org/10.1016/j.neucom.2005.12.126 |
| Huang, G. B., Zhou, H. M., Ding, X. J., et al., 2012. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Transactions on Systems, Man, and Cybernetics Part B, Cybernetics: A Publication of the IEEE Systems, Man, and Cybernetics Society, 42(2): 513–529. https://doi.org/10.1109/tsmcb.2011.2168604 |
| Intrieri, E., Gigli, G., Casagli, N., et al., 2013. Brief Communication "Landslide Early Warning System: Toolbox and General Concepts". Natural Hazards and Earth System Sciences, 13(1): 85–90. https://doi.org/10.5194/nhess-13-85-2013 |
| Khosravi, A., Nahavandi, S., Creighton, D., 2010. A Prediction Interval-Based Approach to Determine Optimal Structures of Neural Network Metamodels. Expert Systems with Applications, 37(3): 2377–2387. https://doi.org/10.1016/j.eswa.2009.07.059 |
| Khosravi, A., Nahavandi, S., Creighton, D., et al., 2011. Comprehensive Review of Neural Network-Based Prediction Intervals and New Advances. IEEE Transactions on Neural Networks, 22(9): 1341–1356. https://doi.org/10.1109/TNN.2011.2162110 |
| Li, C. D., Criss, R. E., Fu, Z. Y., et al., 2021. Evolution Characteristics and Displacement Forecasting Model of Landslides with Stair-Step Sliding Surface along the Xiangxi River, Three Gorges Reservoir Region, China. Engineering Geology, 283: 105961. https://doi.org/10.1016/j.enggeo.2020.105961 |
| Li, D. Y., Yin, K. L., Leo, C., 2010. Analysis of Baishuihe Landslide Influenced by the Effects of Reservoir Water and Rainfall. Environmental Earth Sciences, 60(4): 677–687. https://doi.org/10.1007/s12665-009-0206-2 |
| Li, L. Q., Wang, M. Y., Zhao, H. Q., et al., 2021. Baishuihe Landslide Displacement Prediction Based on CEEMDAN-BA-SVR-Adaboost Model. Journal of Yangtze River Scientific Research Institute, 38(6): 52–59+66 (in Chinese with English Abstract) |
| Li, L. W., Wu, Y. P., Miao, F. S., et al., 2018. Displacement Prediction of Landslides Based on Variational Mode Decomposition and GWO-MIC-SVR Model. Chinese Journal of Rock Mechanics and Engineering, 37(6): 1395–1406. https://doi.org/10.13722/j.cnki.jrme.2017.1508 (in Chinese with English Abstract) |
| Li, L. W., Wu, Y. P., Miao, F. S., et al., 2019. Displacement Interval Prediction Method for Step-Like Landslides Considering Deformation State Dynamic Switching. Chinese Journal of Rock Mechanics and Engineering, 38(11): 2272–2287 (in Chinese with English Abstract) |
| Li, X. Z., Kong, J. M., Wang, Z. Y., 2012. Landslide Displacement Prediction Based on Combining Method with Optimal Weight. Natural Hazards, 61(2): 635–646. https://doi.org/10.1007/s11069-011-0051-y |
| Lian, C., Zeng, Z. G., Yao, W., et al., 2014. Extreme Learning Machine for the Displacement Prediction of Landslide under Rainfall and Reservoir Level. Stochastic Environmental Research and Risk Assessment, 28(8): 1957–1972. https://doi.org/10.1007/s00477-014-0875-6 |
| Liao, K., Wu, Y. P., Li, L. W., et al., 2019. Displacement Prediction Model of Landslide Based on Time Series and GWO-ELM. Journal of Central South University (Science and Technology), 50(3): 619–626 (in Chinese with English Abstract) |
| Lin, D. C., An, F. P., Guo, Z. L., et al., 2011. Prediction of Landslide Displacement by Multi-Modal Support Vector Machine Model. Rock and Soil Mechanics, 32(S1): 451–458. https://doi.org/10.16285/j.rsm.2011.s1.051 (in Chinese with English Abstract) |
| Lins, I. D., Droguett, E. L., das Chagas Moura, M., et al., 2015. Computing Confidence and Prediction Intervals of Industrial Equipment Degradation by Bootstrapped Support Vector Regression. Reliability Engineering & System Safety, 137: 120–128. https://doi.org/10.1016/j.ress.2015.01.007 |
| Liu, Y., Yin, K. L., Chen, L. X., et al., 2016. A Community-Based Disaster Risk Reduction System in Wanzhou, China. International Journal of Disaster Risk Reduction, 19: 379–389. https://doi.org/10.1016/j.ijdrr.2016.09.009 |
| Ma, J. W., Tang, H. M., Liu, X., et al., 2017. Establishment of a Deformation Forecasting Model for a Step-Like Landslide Based on Decision Tree C5.0 and Two-Step Cluster Algorithms: a Case Study in the Three Gorges Reservoir Area, China. Landslides, 14(3): 1275–1281. https://doi.org/10.1007/s10346-017-0804-0 |
| Ma, J. W., Tang, H. M., Liu, X., et al., 2018. Probabilistic Forecasting of Landslide Displacement Accounting for Epistemic Uncertainty: a Case Study in the Three Gorges Reservoir Area, China. Landslides, 15(6): 1145–1153. https://doi.org/10.1007/s10346-017-0941-5 |
| Miao, F. S., Wu, Y. P., Xie, Y. H., et al., 2018. Prediction of Landslide Displacement with Step-Like Behavior Based on Multialgorithm Optimization and a Support Vector Regression Model. Landslides, 15(3): 475–488. https://doi.org/10.1007/s10346-017-0883-y |
| Miao, S. J., Hao, X., Guo, X. L., et al., 2017. Displacement and Landslide Forecast Based on an Improved Version of Saito's Method Together with the Verhulst-Grey Model. Arabian Journal of Geosciences, 10(3): 53. https://doi.org/10.1007/s12517-017-2838-y |
| Mirjalili, S., Mirjalili, S. M., Lewis, A., 2014. Grey Wolf Optimizer. Advances in Engineering Software, 69(3): 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 |
| Phoon, K. K., Kulhawy, F. H., 1999a. Characterization of Geotechnical Variability. Canadian Geotechnical Journal, 36(4): 612–624. https://doi.org/10.1139/t99-038 |
| Phoon, K. K., Kulhawy, F. H., 1999b. Evaluation of Geotechnical Property Variability. Canadian Geotechnical Journal, 36(4): 625–639. https://doi.org/10.1139/t99-039 |
| Posada, D., Buckley, T. R., 2004. Model Selection and Model Averaging in Phylogenetics: Advantages of Akaike Information Criterion and Bayesian Approaches over Likelihood Ratio Tests. Systematic Biology, 53(5): 793–808. https://doi.org/10.1080/10635150490522304 [PubMed] doi: 10.1080/10635150490522304[PubMed |
| Reboredo, J. C., 2011. How Do Crude Oil Prices Co-Move? A Copula Approach. Energy Economics, 33(5): 948–955. https://doi.org/10.1016/j.eneco.2011.04.006 |
| Saito, M., 1965. Forecasting the Time of Occurrence of a Slope Failure. In: Proceedings of the 6th International Mechanics and Foundation Engineering. Pergamon Press, Oxford. 537–541 |
| Sebbar, A., Heddam, S., Djemili, L., 2020. Kernel Extreme Learning Machines (KELM): A New Approach for Modeling Monthly Evaporation (EP) from Dams Reservoirs. Physical Geography, 42(4), 351–373. https://doi.org/10.1080/02723646.2020.1776087 |
| Shrestha, D. L., Solomatine, D. P., 2006. Machine Learning Approaches for Estimation of Prediction Interval for the Model Output. Neural Networks, 19(2): 225–235. https://doi.org/10.1016/j.neunet.2006.01.012 |
| Shrivastava, N. A., Lohia, K., Panigrahi, B. K., 2016. A Multiobjective Framework for Wind Speed Prediction Interval Forecasts. Renewable Energy, 87: 903–910. https://doi.org/10.1016/j.renene.2015.08.038 |
| Shrivastava, N. A., Panigrahi, B. K., 2013. Point and Prediction Interval Estimation for Electricity Markets with Machine Learning Techniques and Wavelet Transforms. Neurocomputing, 118: 301–310. https://doi.org/10.1016/j.neucom.2013.02.039 |
| Sklar, A., 1996. Random Variables, Distribution Functions, and Copulas—A Personal Look Backward and Forward. Institute of Mathematical Statistics Lecture Notes: Monograph Series, 28: 1–14. https://doi.org/10.1214/lnms/1215452606 |
| Tang, J., 2018. Correlation Analysis and Modeling of Power Network Planning Index Based on Copula Function: [Dissertation]. Kunming University of Science and Technology, Kunming (in Chinese with English Abstract) |
| Wan, C., Xu, Z., Wang, Y. L., et al., 2014. A Hybrid Approach for Probabilistic Forecasting of Electricity Price. IEEE Transactions on Smart Grid, 5(1): 463–470. https://doi.org/10.1109/TSG.2013.2274465 |
| Wang, L., 2018. The Method of Optimum Combined Power Load Forecasting Based on Differential Evolution Optimization Weight: [Dissertation]. Tianjin University, Tianjin (in Chinese with English Abstract) |
| Wang, X. L., Xie, H. Y., Wang, J. J., et al., 2020. Prediction of Dam Deformation Based on Bootstrap and ICS-MKELM Algorithms. Journal of Hydroelectric Engineering, 39(3): 106–120 (in Chinese with English Abstract) |
| Wang, Y. K., Tang, H. M., Wen, T., et al., 2019. A Hybrid Intelligent Approach for Constructing Landslide Displacement Prediction Intervals. Applied Soft Computing, 81: 105506. https://doi.org/10.1016/j.asoc.2019.105506 |
| Wu, X. L., Zhan, F. B., Zhang, K. X., et al., 2016. Application of a Two-Step Cluster Analysis and the Apriori Algorithm to Classify the Deformation States of Two Typical Colluvial Landslides in the Three Gorges, China. Environmental Earth Sciences, 75(2): 146–161. https://doi.org/10.1007/s12665-015-5022-2 |
| Xiang, Q. L., 2012. Study for Dam Deformation Monitoring Data Based On Time Series Anylysis: [Dissertation]. Northwest A & F University, Yanglin (in Chinese with English Abstract) |
| Xu, S. L., Niu, R. Q., 2018. Displacement Prediction of Baijiabao Landslide Based on Empirical Mode Decomposition and Long Short-Term Memory Neural Network in Three Gorges Area, China. Computers & Geosciences, 111: 87–96. https://doi.org/10.1016/j.cageo.2017.10.013 |
| Yang, M., Yang, C. L., Dong, J. C., 2019. Ultra-Short Term Probabilistic Intervals Forecasting of Wind Power Based on Optimization Model of Forecasting Error Distribution. Acta Energiae Solaris Sinica, 40(10): 2067–2978 (in Chinese with English Abstract) |
| Yang, X. Y., Zhang, Y. F., Ye, T. Z., et al., 2020. Prediction of Combination Probability Interval of Wind Power Based on Naive Bayes. High Voltage Engineering, 46(3): 1099–1108 (in Chinese with English Abstract) |
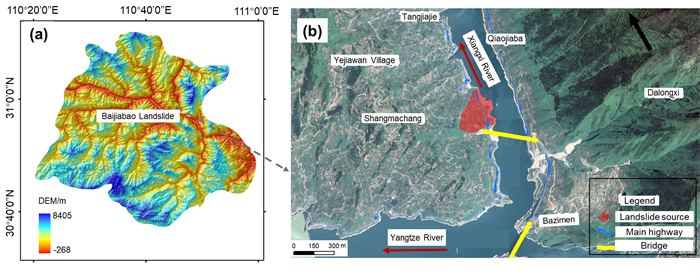
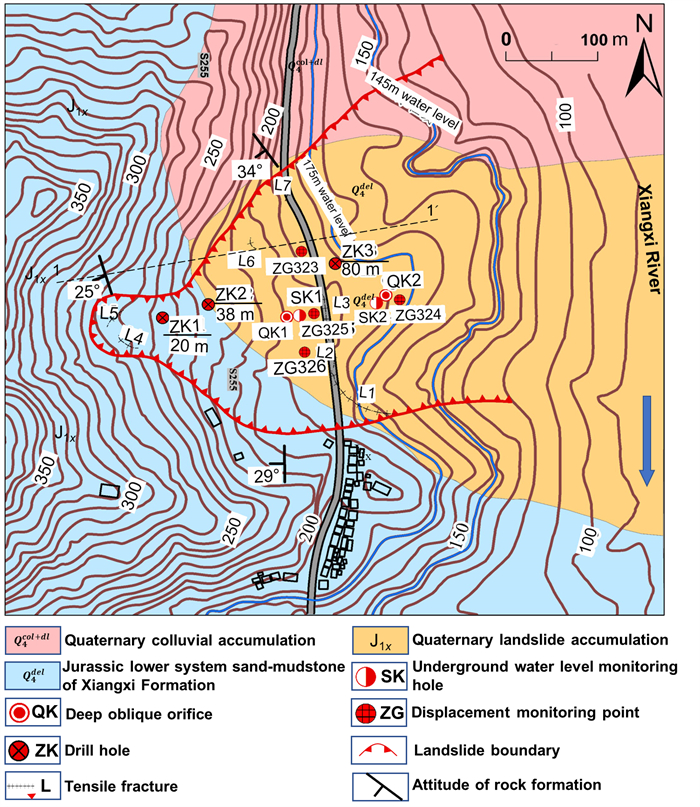
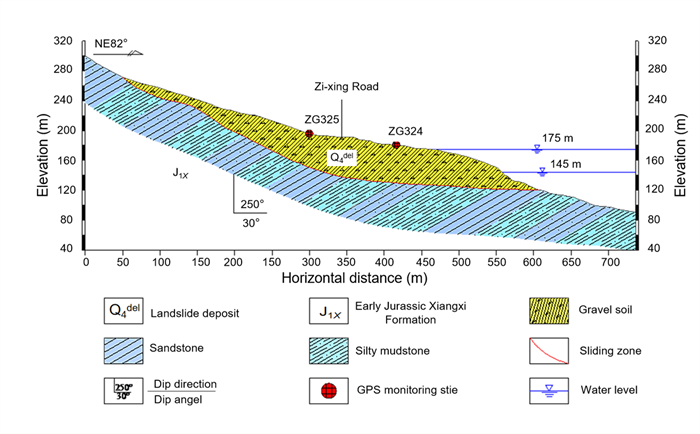
| Yao, W. M., Li, C. D., Zuo, Q. J., et al., 2019. Spatiotemporal Deformation Characteristics and Triggering Factors of Baijiabao Landslide in Three Gorges Reservoir Region, China. Geomorphology, 343: 34–47. https://doi.org/10.1016/j.geomorph.2019.06.024 |
| Yao, W., Zeng, Z. G., Lian, C., et al., 2015. Training Enhanced Reservoir Computing Predictor for Landslide Displacement. Engineering Geology, 188: 101–109. https://doi.org/10.1016/j.enggeo.2014.11.008 |
| Yin, K. L., Yan, T. Z., 1996. Landslide Prediction and Related Models. China Journal of Rock Mechanics and Engineering, 1: 1–8 (in Chinese with English Abstract) |
| Yin, Y. P., Wang, H. D., Gao, Y. L., et al., 2010. Real-Time Monitoring and Early Warning of Landslides at Relocated Wushan Town, the Three Gorges Reservoir, China. Landslides, 7(3): 339–349. https://doi.org/10.1007/s10346-010-0220-1 |
| Zhang, K., Zhang, K., Bao, R., et al., 2021. Intelligent Prediction of Landslide Displacements Based on Optimized Empirical Mode Decomposition and K-Mean Clustering. Rock and Soil Mechanics, 42(1): 211–223 (in Chinese with English Abstract) |
| Zhou, C., Yin, K. L., Cao, Y., et al., 2016. Application of Time Series Analysis and PSO-SVM Model in Predicting the Bazimen Landslide in the Three Gorges Reservoir, China. Engineering Geology, 204: 108–120. https://doi.org/10.1016/j.enggeo.2016.02.009 |
Figures(11) / Tables(5)
Copyright © 2013-2020 Journal of Earth Science 鄂ICP备15021562号-2
Tel: +86-27-67885075 Fax: +86-27-67885075 E-mail: xbb@cug.edu.cn
Address: Editorial Office of Journal, China University of Geosciences, Yujiashan, Wuhan, Hubei 430074, P. R. China
Supported by:
Beijing Renhe Information Technology Co. Ltd
E-mail:
info@rhhz.net



 DownLoad:
DownLoad: