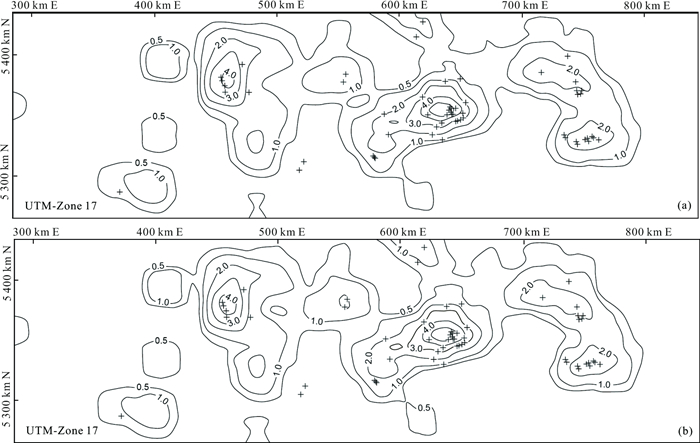
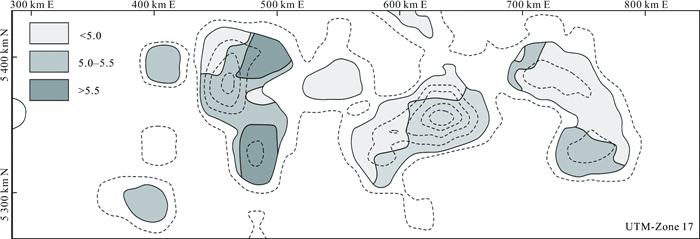
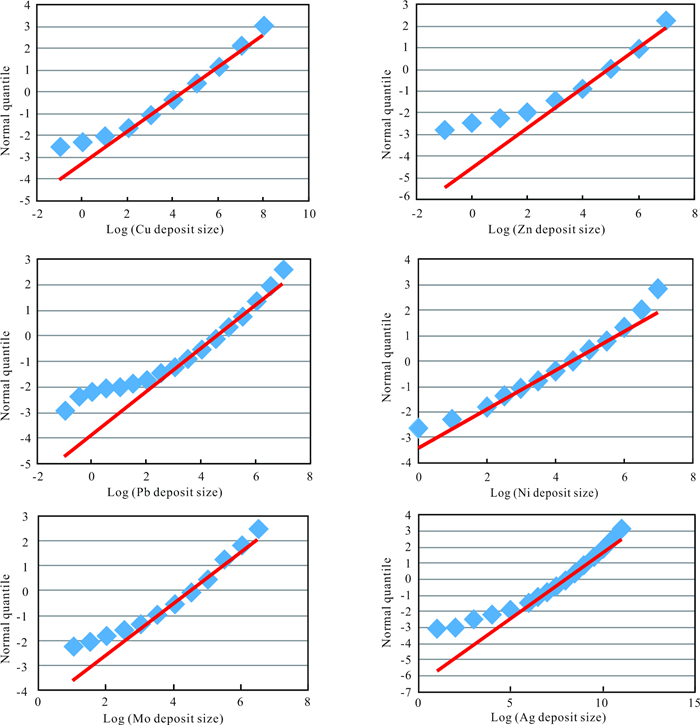
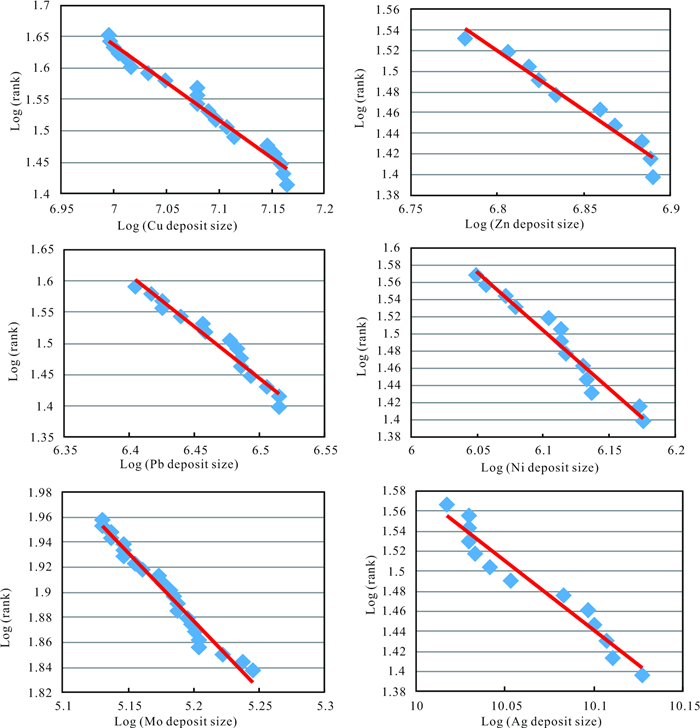
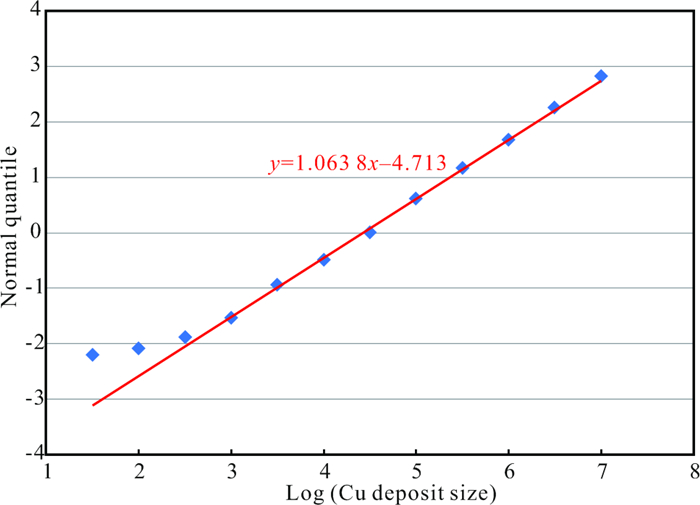
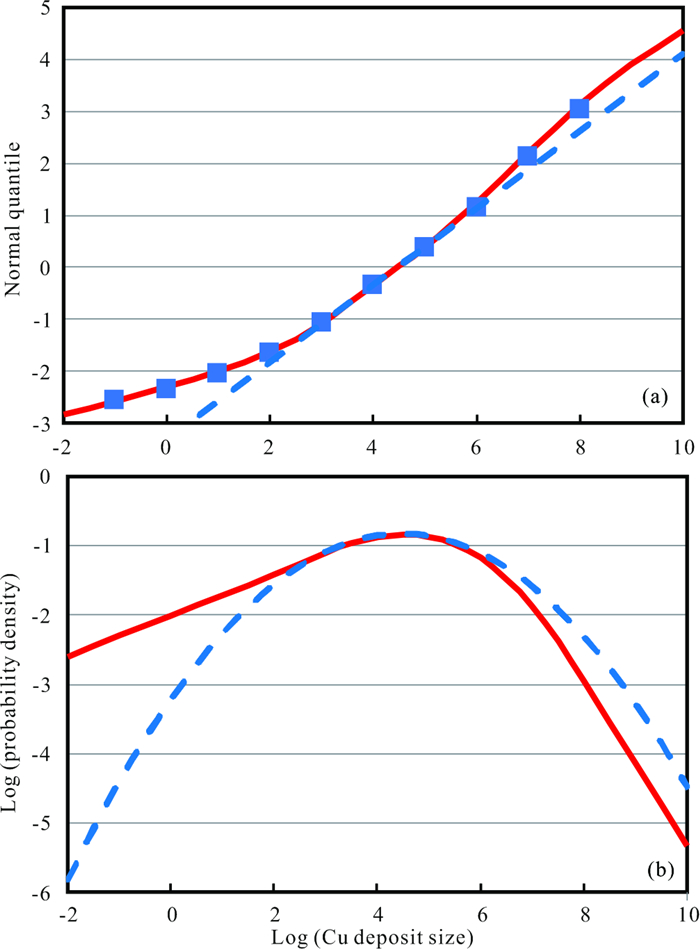
| Citation: | Frits Agterberg. Aspects of Regional and Worldwide Mineral Resource Prediction. Journal of Earth Science, 2021, 32(2): 279-287. doi: 10.1007/s12583-020-1397-4

|
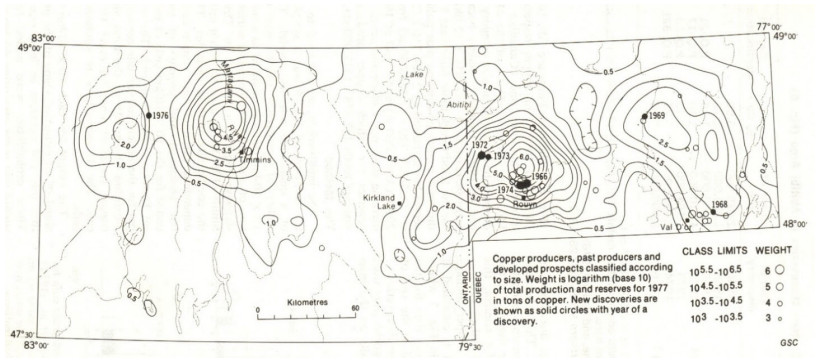
| Agterberg, F. P., Chung, C. F., Fabbri, A. G., et al., 1972. Geomathematical Evaluation of Copper and Zinc Potential of the Abitibi Area, Ontario and Quebec. Geological Survey of Canada, 41-71 http://www.getcited.org/pub/101554608 |
| Agterberg, F. P., 1973. Probabilistic Models to Evaluate Regional Mineral Potential. In: Proc. Symposium on Mathematical Methods in the Geosciences, Přibram. 3-38 |
| Agterberg, F. P., 2013. Fractals and Spatial Statistics of Point Patterns. Journal of Earth Science, 24(1): 1-11. https://doi.org/10.1007/s12583-013-0305-6 |
| Agterberg, F. P., 2014. Geomathematics: Theoretical Foundations, Applications and Future Developments. Springer, Heidelberg. 553 |
| Agterberg, F. P., 2017a. Pareto-lognormal Modeling of Known and Unknown Metal Resources. Natural Resources Research, 26: 3-20. https://doi.org/10.1007/s11053-016-9305-4 |
| Agterberg, F. P., 2017b. Pareto-Lognormal Modeling of Known and Unknown Metal Resources. Ⅱ. Method Refinement and Further Applications. Natural Resources Research, 26(3): 265-283. https://doi.org/10.1007/s11053-017-9327-6 |
| Agterberg, F. P., 2018b. Statistical Modeling of Regional and Worldwide Size-Frequency Distributions of Metal Deposits. In: Daya Sagar, B. S., Cheng, Q. M., Agterberg, F. P., eds., Handbook of Mathematical Geosciences. Fifty Years of IAMG. Springer, Heidelberg. 505-527 |
| Agterberg, F. P., 2018c. New Method of Fitting Pareto-Lognormal Size-Frequency Distributions of Metal Deposits. Natural Resources Research 27(1): 265-283 |
| Agterberg, F. P., 2020. Multifractal Modeling of Worldwide and Canadian Metal Size-Frequency Distributions. Natural Resources Research, 29(1): 539-550. https://doi.org/10.1007/s11053-019-09460-1 |
| Agterberg, F. P., David, M., 1979. Statistical Exploration. In: Weiss, A., ed., Computer Methods for the 80's. Society of Mining Engineers, New York. 30-115 |
| Agterberg, F. P., 2018a. Can Multifractals be Used for Mineral Resource Appraisal?. Journal of Geochemical Exploration, 189: 54-63. https://doi.org/10.1016/j.gexplo.2017.06.022 |
| Agterberg, F. P., 1970. Autocorrelation Functions in Geology. In: Merriam, D. F., ed., Geostatistics, Plenum, New York. 113-142 |
| Bonham-Carter, G. F., 1994. Geographic Information Systems for geoscientists: Modelling with GIS. Pergamon, Oxford. 398 |
| Carlson, C. A., 1991. Spatial Distribution of Ore Deposits. Geology, 19(2): 111-114. https://doi.org/10.1130/0091-7613(1991)019<0111:sdood>2.3.co;2 doi: 10.1130/0091-7613(1991)019<0111:sdood>2.3.co;2 |
| Cheng, Q. M., 2007. Mapping Singularities with Stream Sediment Geochemical Data for Prediction of Undiscovered Mineral Deposits in Gejiu, Yunnan Province, China. Ore Geology Reviews, 32(1/2): 314-324. https://doi.org/10.1016/j.oregeorev.2006.10.002 |
| Efron, B., 1982. The Jackknife, the Bootstrap and Other Resampling Plans: SIAM, Philadelphia. 93 |
| Kleiber, C., Kotz, S., 2003. Statistical Distributions in Economics and Actuarial Sciences. Wiley, Hoboken. 339 |
| Lydon, J. W., 2007. An Overview of Economic and Geological Contexts of Canada's Major Mineral Deposit Types. In: Goodfellow, M. D., ed., Mineral Deposits of Canada: A Synthesis of Major Deposit Types, District Metallogeny, the Evolution of Geological Provinces & Exploration Methods. Geological Association of Canada, Mineral Deposits Division, Special Publication No. 5, Montreal. 3-48 |
| Mandelbrot, B. B., 1975. Les Objects Fractals: Forme, Hazard et Dimension. Flammarion, Paris. 346 |
| Patiño Douce, A. E., 2016a. Metallic Mineral Resources in the Twenty-First Century. I. Historical Extraction Trends and Expected Demand. Natural Resources Research, 25(1): 71-90. https://doi.org/10.1007/s11053-015-9266-z |
| Patiño Douce, A. E., 2016b. Metallic Mineral Resources in the Twenty First Century. Ⅱ. Constraints on Future Supply. Natural Resources Research, 25: 97-124. https://doi.org/10.1007/s11053-015-9265-0 |
| Patiño Douce, A. E., 2016c. Statistical Distribution Laws for Metallic Mineral Deposit Sizes. Natural Resources Research, 25: 365-387. https://doi.org/10.1007/s11053-016-9297-0 |
| Patiño Douce, A. E., 2017. Loss Distribution Model for Metal Discovery Probabilities. Natural Resources Research, 26: 241-263. https://doi.org/10.1007/s11053-016-9315-2 |
| Quandt, R. E., 1966. Old and New Methods of Estimation and the Pareto Distribution. Metrica, 10: 55-82 doi: 10.1007/BF02613419 |
| Quenouille, M., 1949. Approximate Tests of Correlation in Time Series. Journal of the Royal Statistical Society, Series B, 27: 395-449 http://www.ams.org/mathscinet-getitem?mr=30179 |
| Reed, W. J., 2003. The Pareto Law of Increases: An Explanation and an Extension. Physica A., 319: 579-597 doi: 10.1016/S0378-4371(02)01455-3 |
| Reed, W. J., Jorgensen, M., 2003. The Double Pareto-Lognormal Distribution. A New Parametric Model for Size Distributions. Computational Statistics: Theory and Methods, 33(8): 1733-1753 doi: 10.1081/STA-120037438 |
| Ripley, B. D., 1976. The Second-Order Analysis of Stationary Point Processes. Journal of Applied Probability, 13: 255-266 doi: 10.2307/3212829 |
| Singer, D., Menzie, W. D., 2010. Quantitative Mineral Resource Assessments: An Integrated Approach. Oxford University Press, New York |
| Tukey, J. W., 1970. Some Further Inputs. In: Merriam, D. F., ed., Geostatistics. Plenum, New York. 163-174 |
| USGS, 2015. Mineral Commodity Summaries 2015. U.S. Geological Survey, Reston |
| Zhao, P., Hu, W., Li, Z., 1983. Statistical Prediction of Mineral Deposits. Geological Publishing House, Beijing (in Chinese) |
Figures(9) / Tables(1)
Copyright © 2013-2020 Journal of Earth Science 鄂ICP备15021562号-2
Tel: +86-27-67885075 Fax: +86-27-67885075 E-mail: xbb@cug.edu.cn
Address: Editorial Office of Journal, China University of Geosciences, Yujiashan, Wuhan, Hubei 430074, P. R. China
Supported by:
Beijing Renhe Information Technology Co. Ltd
E-mail:
info@rhhz.net



 DownLoad:
DownLoad: