| Citation: | Yongliang Chen, Shicheng Wang, Qingying Zhao, Guosheng Sun. Detection of Multivariate Geochemical Anomalies Using the Bat-Optimized Isolation Forest and Bat-Optimized Elliptic Envelope Models. Journal of Earth Science, 2021, 32(2): 415-426. doi: 10.1007/s12583-021-1402-6

|
| Breunig, M. M., Kriegel, H. P., Ng, R. T., et al., 2000. LOF: Identifying Density-Based Local Outliers. ACM SIGMOD Conference 2000, Dallas |
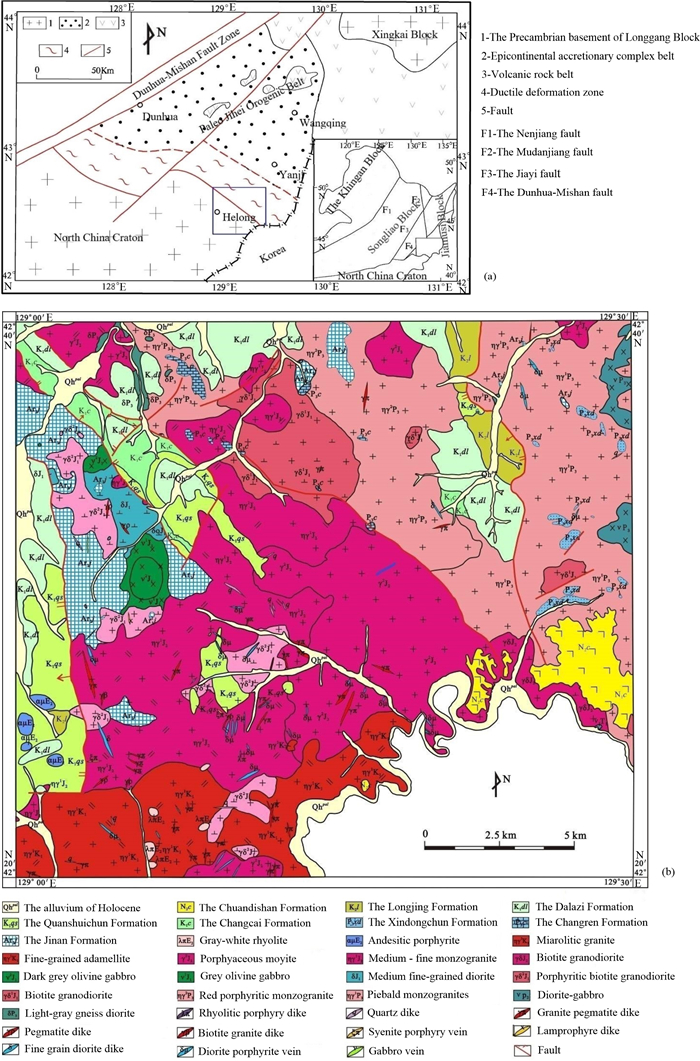
| Chai, S. L., Liu, Z. H., 2015. Experimental Demonstration on 1: 50000 Scale Mineral Geology Survey of Four Geological Maps in the Helong Area, Jilin Province. Mineral Geology Survey Report (Internal Communication), Jilin University, Changchun. 205(in Chinese) |
| Chen, Y. L., Lu, L. J., Li, X. B., 2014a. Kernel Mahalanobis Distance for Multivariate Geochemical Anomaly Recognition. Journal of Jilin University (Earth Science Edition), 44(1): 396-408(in Chinese) http://en.cnki.com.cn/Article_en/CJFDTOTAL-CCDZ201401040.htm |
| Chen, Y. L., Lu, L. J., Li, X. B., 2014b. Application of Continuous Restricted Boltzmann Machine to Identify Multivariate Geochemical Anomaly. Journal of Geochemical Exploration, 140: 56-63. https://doi.org/10.1016/j.gexplo.2014.02.013 |
| Chen, Y. L., 2015. Mineral Potential Mapping with a Restricted Boltzmann Machine. Ore Geology Reviews, 71: 749-760. https://doi.org/10.1016/j.oregeorev.2014.08.012 |
| Chen, Y. L., Wu, W., 2016. A Prospecting Cost-Benefit Strategy for Mineral Potential Mapping Based on ROC Curve Analysis. Ore Geology Reviews, 74: 26-38. https://doi.org/10.1016/j.oregeorev.2015.11.011 |
| Chen, Y., Wu, W., 2017a. Mapping Mineral Prospectivity by Using One-Class Support Vector Machine to Identify Multivariate Geological Anomalies from Digital Geological Survey Data. Australian Journal of Earth Sciences, 64(5): 639-651. https://doi.org/10.1080/08120099.2017.1328705 |
| Chen, Y. L., Wu, W., 2017b. Mapping Mineral Prospectivity Using an Extreme Learning Machine Regression. Ore Geology Reviews, 80: 200-213. https://doi.org/10.1016/j.oregeorev.2016.06.033 |
| Chen, Y. L., Wu, W., 2017c. Application of One-Class Support Vector Machine to Quickly Identify Multivariate Anomalies from Geochemical Exploration Data. Geochemistry: Exploration, Environment, Analysis, 17(3): 231-238. https://doi.org/10.1144/geochem2016-024 |
| Chen, Y. L., Wu, W., 2019a. Isolation Forest as an Alternative Data-Driven Mineral Prospectivity Mapping Method with a Higher Data-Processing Efficiency. Natural Resources Research, 28(1): 31-46. https://doi.org/10.1007/s11053-018-9375-6 |
| Chen, Y. L., Wu, W., 2019b. Separation of Geochemical Anomalies from the Sample Data of Unknown Distribution Population Using Gaussian Mixture Model. Computers & Geosciences, 125: 9-18. https://doi.org/10.1016/j.cageo.2019.01.010 |
| Chen, Y. L., Wu, W., Zhao, Q. Y., 2019a. A Bat Algorithm-Based Data-Driven Model for Mineral Prospectivity Mapping. Natural Resources Research, 29(1): 247-265. https://doi.org/10.1007/s11053-019-09589-z |
| Chen, Y. L., Wu, W., Zhao, Q. Y., 2019b. A Bat-Optimized One-Class Support Vector Machine for Mineral Prospectivity Mapping. Minerals, 9(5): 317. https://doi.org/10.3390/min9050317 |
| Gałuszka, A., 2007. A Review of Geochemical Background Concepts and an Example Using Data from Poland. Environmental Geology, 52(5): 861-870. https://doi.org/10.1007/s00254-006-0528-2 |
| Goyal, S., Patterh, M. S., 2013. Wireless Sensor Network Localization Based on Bat Algorithm. International Journal of Emerging Technologies in Computational and Applied Sciences (IJETCAS), 4(5): 507-512 |
| Liu, F. S., Zhang, M. L., 1999. Complete Quality Management of the New-Round Land Resources Survey. Chinese Geology, 267(8): 20-21(in Chinese) |
| Liu, F. T., Ting, K. M., Zhou, Z. H., 2008. Isolation Forest. Proceedings of the Eighth IEEE International Conference on Data Mining (ICDM), 413-422 |
| Pan, Y. D., Xu, B. J., Sun, Y., et al., 2016. Geological Features of the Jinchengdong Gold Deposit in Helong City, Jilin Province, China. Jilin Geology, 35(1): 30-35(in Chinese) http://en.cnki.com.cn/Article_en/CJFDTOTAL-JLDZ201601007.htm |
| Rousseeuw, P. J., 1984. Least Median of Squares Regression. Journal of the American Statistical Association, 79(388): 871-880. https://doi.org/10.1080/01621459.1984.10477105 |
| Rousseeuw, P. J., van Driessen, K. V., 1999. A Fast Algorithm for the Minimum Covariance Determinant Estimator. Technometrics, 41(3): 212-223. https://doi.org/10.1080/00401706.1999.10485670 |
| Sharawi, M., Emary, E., Saroit, I. A., et al., 2012. Bat Swarm Algorithm for Wireless Sensor Networks Lifetime Optimization. International Journal of Science and Research (IJSR), 3(5): 655-664 http://www.researchgate.net/publication/270241192_Bat_Swarm_Algorithm_for_Wireless_Sensor_Networks_Lifetime_Optimization |
| Wan, W. Z., Wang, J. B., Feng, X. Y., et al., 2010. Geological Features and Prospecting Directions of the Heanhe Gold Deposit in the Helong Area, Jilin Province, China. Jilin Geology, 29(1): 71-75(in Chinese) http://en.cnki.com.cn/Article_en/CJFDTotal-JLDZ201004015.htm |
| Wu, F., Lin, J., Wilde, S., et al., 2005. Nature and Significance of the Early Cretaceous Giant Igneous Event in Eastern China. Earth and Planetary Science Letters, 233(1/2): 103-119. https://doi.org/10.1016/j.epsl.2005.02.019 |
| Wu, P. F., Sun, D. Y., Wang, T. H., et al., 2013. Chronology, Geochemical Characteristic and Petrogenesis Analysis of Diorite in Helong of Yanbian Area, Northeastern China. Geological Journal of China Universities, 19(4): 600-610(in Chinese) http://en.cnki.com.cn/Article_en/CJFDTOTAL-GXDX201304006.htm |
| Wu, W., Chen, Y. L., 2018. Application of Isolation Forest to extract Multivariate Anomalies from Geochemical Exploration Data. Global Geology, 21(1): 36-47. https://doi.org/10.3969/j.issn.1673-9736.2018.01.04 |
| Xiong, Y. H., Zuo, R. G., 2016. Recognition of Geochemical Anomalies Using a Deep Autoencoder Network. Computers & Geosciences, 86: 75-82. https://doi.org/10.1016/j.cageo.2015.10.006 |
| Yan, D., Li, N., Xu, M., et al., 2015. Mineralization Characteristics and Genesis of the Bailiping Silver Deposit in Helong City, Jilin Province. Jilin Geology, 34(3): 36-41(in Chinese) http://www.zhangqiaokeyan.com/academic-journal-cn_jilin-geology_thesis/0201253935009.html |
| Yang, X. S., Gandomi, A. H., 2012. Bat Algorithm: A Novel Approach for Global Engineering Optimization. Engineering Computations, 29(5): 464-483. https://doi.org/10.1108/02644401211235834 |
| Yang, X. S., 2010. A new Metaheuristic Bat-Inspired Algorithm. In: Juan, R. G., David, A. P., Carlos, C., et al., eds., Nature Inspired Cooperative Strategies for Optimization. Springer-Verlag, Berlin. 65-74 |
| Yu, J. J., Wang, F., Xu, W. L., et al., 2012. Early Jurassic Mafic Magmatism in the Lesser Xing'an-Zhangguangcai Range, NE China, and Its Tectonic Implications: Constraints from Zircon U-Pb Chronology and Geochemistry. Lithos, 142/143:256-266. https://doi.org/10.1016/j.lithos.2012.03.016 |
| Zhang, Y. B., Wu, F. Y., Wilde, S. A., et al., 2004. Zircon U-Pb Ages and Tectonic Implications of 'Early Paleozoic' Granitoids at Yanbian, Jilin Province, Northeast China. The Island Arc, 13(4): 484-505. https://doi.org/10.1111/j.1440-1738.2004.00442.x |
| Zheng, Z. Y., 2019. A Comparison between Several Machine Learning Methods for Multivariate Geochemical Anomaly Identification in the Helong Area, Jilin Province: [Dissertation]. Jilin University, Changchun. 40-50(in Chinese with English Abstract) |
Figures(6) / Tables(3)
Copyright © 2013-2020 Journal of Earth Science 鄂ICP备15021562号-2
Tel: +86-27-67885075 Fax: +86-27-67885075 E-mail: xbb@cug.edu.cn
Address: Editorial Office of Journal, China University of Geosciences, Yujiashan, Wuhan, Hubei 430074, P. R. China
Supported by:
Beijing Renhe Information Technology Co. Ltd
E-mail:
info@rhhz.net



 DownLoad:
DownLoad: